How to Import and Export Data in Stata|2025
/in STATA Articles /by BesttutorHow to Import and Export Data in Stata provides a detailed guide to transferring data seamlessly. Learn the steps to import datasets from various formats and export your results for analysis and reporting.
Stata is a powerful statistical software widely used in various fields for data analysis, manipulation, and visualization. One of the essential skills in working with Stata is understanding how to import and export data. The process of data importation and exportation enables users to seamlessly work with data stored in different formats, including Excel, CSV files, and other delimited text formats. This paper provides an in-depth overview of how to import and export data in Stata, focusing on common data formats such as Excel and CSV. Additionally, it will cover essential techniques for customizing the import and export process to fit specific user requirements.
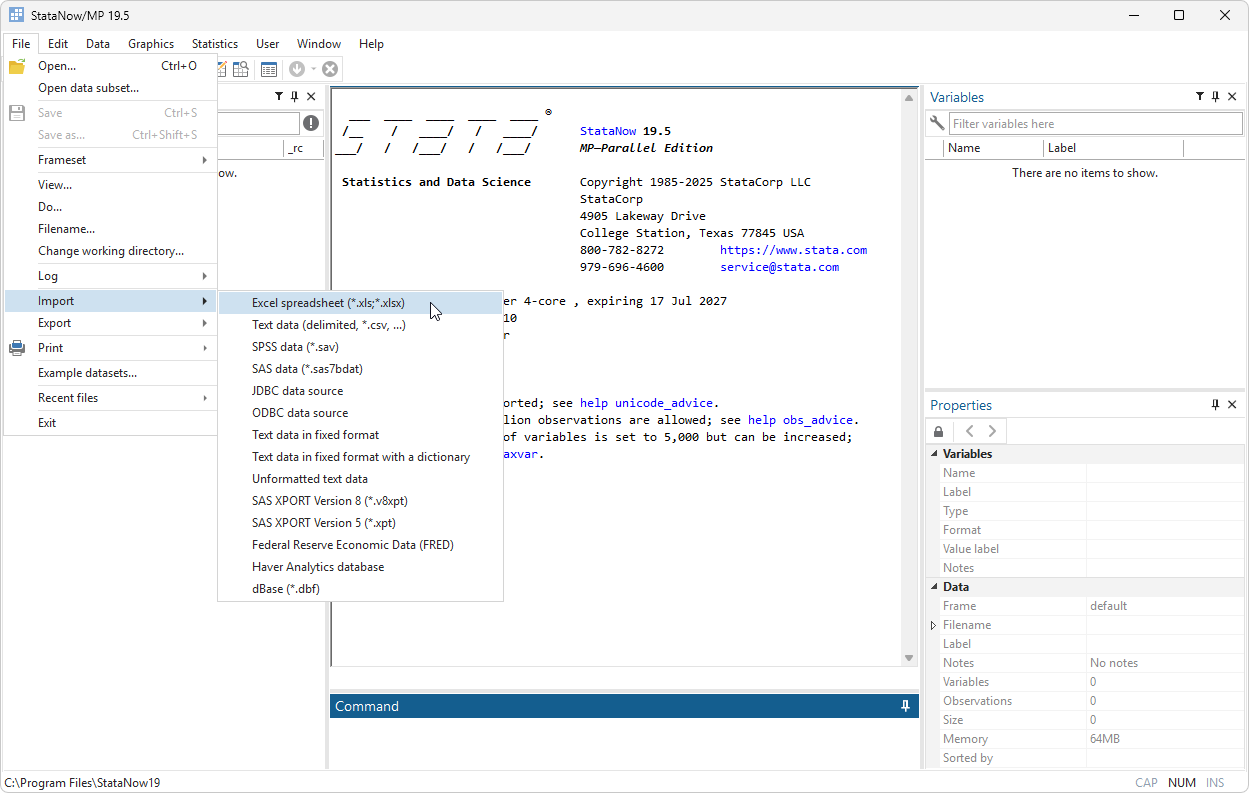
Importing Data into Stata
Stata Import Excel
Stata provides a straightforward command to import data from Excel files. The import excel command is used to read Excel files (both .xls and .xlsx) into Stata. By using this command, users can quickly load data from Excel sheets without the need for manual data entry.
The basic syntax for importing Excel files into Stata is as follows:
import excel using "filename.xlsx", sheet("Sheet1")
This command tells Stata to import data from an Excel file named filename.xlsx located in the current working directory and to import data from the sheet named Sheet1. If you do not specify a sheet name, Stata will default to importing the first sheet in the Excel file.
In addition to the sheet option, the import excel command also supports other useful options, such as:
firstrow: This option tells Stata to treat the first row in the Excel sheet as variable names.
Example:
import excel using "data.xlsx", sheet("Sheet1") firstrow
This command ensures that the variable names in Stata are taken from the first row of the Excel sheet.
clear: Theclearoption clears the current dataset in memory before importing the new data.
Example:
import excel using "data.xlsx", sheet("Sheet1") firstrow clear
1.2 Stata Import CSV
CSV (Comma Separated Values) is a popular format for storing tabular data. Stata offers the import delimited command to import data from CSV files. The import delimited command reads CSV files and other delimited text files, converting them into Stata datasets.
The basic syntax for importing CSV files is:
import delimited "filename.csv", clear
This command tells Stata to import data from the file filename.csv and load it into memory. By default, Stata treats commas as delimiters, but this command also supports other delimiters, such as tabs or semicolons. For example, to specify a semicolon as the delimiter, you would use the delimiter() option:
import delimited "filename.csv", delimiter(";") clear
Another important option for importing CSV files is varnames, which specifies how variable names should be treated. By default, Stata assumes that the first row contains variable names. However, if your CSV file does not contain variable names in the first row, you can use the varnames(0) option to tell Stata to generate default variable names.
Example:
import delimited "filename.csv", delimiter(",") varnames(0) clear

Exporting Data from Stata
Once data has been processed and analyzed in Stata, it is often necessary to export the results to a different format for further analysis or reporting. Stata provides a range of commands for exporting data to formats such as Excel and CSV.
How to Export Data from Stata to Excel
One of the most common formats for exporting data from Stata is Excel. Stata provides the export excel command, which allows users to save their Stata datasets as Excel files. The basic syntax for exporting data to Excel is:
export excel using "filename.xlsx", firstrow(varlabels)
This command exports the current Stata dataset to an Excel file named filename.xlsx and includes the variable labels in the first row of the Excel sheet.
In addition to the firstrow(varlabels) option, there are other useful options available when exporting to Excel:
sheet("SheetName"): This option allows users to specify the sheet name in the Excel file.
Example:
export excel using "filename.xlsx", sheet("Data") firstrow(varlabels)
replace: This option overwrites an existing Excel file if one already exists with the same name.
Example:
export excel using "filename.xlsx", sheet("Data") replace
sheetmodify: Thesheetmodifyoption allows users to modify an existing Excel sheet. This option is useful when you want to update data in an existing sheet without overwriting the entire file.
Example:
export excel using "filename.xlsx", sheet("Data") sheetmodify firstrow(varlabels)
Stata Export Data to Excel with Variable Names
By default, when exporting to Excel using export excel, the variable names are included as column headers. However, if you prefer to include the variable names as the first row of data (instead of using variable labels), you can specify the firstrow(variable) option.
Example:
export excel using "filename.xlsx", firstrow(variable)
This command will export the Stata dataset to Excel, placing the variable names in the first row instead of the variable labels.
Export Excel Firstrow Stata
The firstrow option in the export excel command is crucial when dealing with Excel exports. You can control whether variable names or labels appear in the first row of the exported file. The firstrow(varlabels) option includes variable labels as column headers, while the firstrow(variable) option includes variable names.
Example with variable names:
export excel using "filename.xlsx", firstrow(variable)
Example with variable labels:
export excel using "filename.xlsx", firstrow(varlabels)
Stata Export Excel Sheet Modify
The sheetmodify option is useful when you want to append data to an existing sheet or update the data in a specific sheet. This option modifies the data in an existing Excel sheet rather than creating a new one.
Example:
export excel using "filename.xlsx", sheet("Data") sheetmodify
This command will add the current Stata dataset to the Data sheet in the existing Excel file filename.xlsx.
Stata Export CSV
Exporting data to CSV is another common task. The export delimited command in Stata is used to export datasets to CSV files. The basic syntax for exporting a Stata dataset to a CSV file is:
export delimited using "filename.csv", replace
This command exports the Stata dataset to a CSV file named filename.csv, replacing any existing file with the same name.
If you want to customize the delimiters used in the CSV file, you can use the delimiter() option. For example, to use a tab character as the delimiter:
export delimited using "filename.csv", delimiter(tab) replace
Additionally, you can control whether variable names are included in the first row of the CSV file by using the varnames() option:
export delimited using "filename.csv", varnames(1) replace
This command ensures that the variable names appear in the first row of the CSV file.

Conclusion
Importing and exporting data in Stata is a fundamental skill for working with external data files. By mastering commands such as import excel, import delimited, export excel, and export delimited, users can efficiently handle data stored in Excel, CSV, and other formats. Customizing the import and export process through various options, such as firstrow, clear, and replace, allows users to tailor their workflows to specific needs. Whether working with raw data or sharing results with others, Stata’s data import and export functionality ensures seamless integration with other software and facilitates effective data analysis and reporting.
By understanding how to manipulate these commands and options, users can improve their productivity and ensure that their data is consistently formatted and ready for analysis.
Needs help with similar assignment?
We are available 24x7 to deliver the best services and assignment ready within 3-4 hours? Order a custom-written, plagiarism-free paper





:max_bytes(150000):strip_icc()/Descriptive_statistics-5c8c9cf1d14d4900a0b2c55028c15452.png)