Step-by-Step Guide to Completing SPSS Assignments|2025
Master data analysis with this Step-by-Step Guide to Completing SPSS Assignments. Ideal for students and professionals, this guide walks you through data entry, test selection, output interpretation, and report writing to ensure accuracy and success in your SPSS projects.
Introduction
SPSS (Statistical Package for the Social Sciences) is a powerful tool for statistical analysis, widely used in academic research, business analytics, and social sciences. However, many students struggle with SPSS assignments due to its complex interface and the need for statistical knowledge.
This step-by-step guide will walk you through the entire process of completing an SPSS assignment—from data entry and cleaning to running statistical tests and interpreting results. By the end, you’ll have a structured approach to tackle any SPSS task efficiently.
Understanding the Assignment Requirements
Before opening SPSS, carefully read your assignment instructions to determine:
✔ Research question/hypothesis (What are you testing?)
✔ Variables involved (Independent/Dependent, Measurement scales)
✔ Statistical tests required (T-tests, ANOVA, Regression, Chi-Square, etc.)
✔ Output expectations (Tables, graphs, written interpretation)
Example Assignment Prompt:
“Compare the mean exam scores of male and female students using an independent samples t-test. Report descriptive statistics, test results, and a brief interpretation.”
Key Tasks Identified:
-
Enter/import data.
-
Run descriptive statistics.
-
Conduct an independent samples t-test.
-
Interpret and report results.
Preparing and Entering Data in SPSS
Step 1: Open SPSS and Set Up Variables
-
Launch SPSS → Click “Variable View” (bottom-left tab).
-
Define each variable:
-
Name (e.g., “Gender,” “Exam_Score”)
-
Type (Numeric for quantitative, String for text)
-
Label (Full description, e.g., “Student Gender”)
-
Values (For categorical variables, e.g., 1 = Male, 2 = Female)
-
Measure (Nominal, Ordinal, Scale)
-
Example Variable Setup:
| Name | Type | Label | Values | Measure |
|---|---|---|---|---|
| Gender | Numeric | Student Gender | 1=Male, 2=Fem | Nominal |
| Exam_Score | Numeric | Final Exam (%) | – | Scale |
Step 2: Enter Data in “Data View”
-
Switch to “Data View” (top-left tab).
-
Manually input data or import from Excel (File → Open → Data → Select .xlsx file).
Example Data Entry:
| Gender | Exam_Score |
|---|---|
| 1 | 85 |
| 2 | 92 |
| 1 | 78 |

Cleaning and Screening Data
Before analysis, check for:
✔ Missing values (Analyze → Descriptive Statistics → Frequencies)
✔ Outliers (Graphs → Boxplots)
✔ Normality (Shapiro-Wilk test: Analyze → Descriptive → Explore → Plots → Normality)
Fixing Issues:
-
Missing Data: Use “Recode” or “Replace Missing Values” (Transform menu).
-
Outliers: Decide whether to exclude or transform (e.g., log transformation).
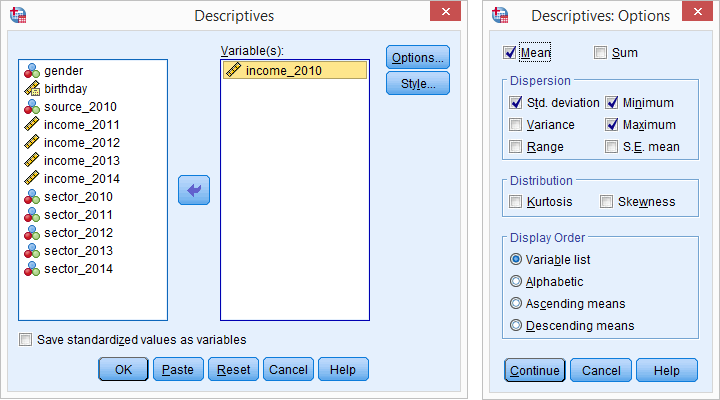
Running Descriptive Statistics
Purpose: Summarize key features of the data.
Steps:
-
Analyze → Descriptive Statistics → Descriptives/Frequencies
-
Select variables (e.g., Exam_Score).
-
Click “Options” to include Mean, SD, Min, Max.
Example Output:
| N | Mean | Std. Deviation | |
|---|---|---|---|
| Exam_Score | 30 | 80.2 | 9.5 |
Interpretation:
-
The average exam score is 80.2% with moderate variability (SD = 9.5).
Conducting Statistical Tests
Case 1: Independent Samples T-Test (Comparing Two Groups)
Steps:
-
Analyze → Compare Means → Independent-Samples T-Test
-
Move Exam_Score to “Test Variable(s).”
-
Move Gender to “Grouping Variable” → Define Groups (1 and 2).
-
Click OK.
Interpreting Output:
-
Group Statistics: Compare means (e.g., Males: 78.5, Females: 82.0).
-
Levene’s Test: If p > 0.05, assume equal variances.
-
T-Test Results: Check Sig. (2-tailed). If p < 0.05, the difference is significant.
Reporting:
*”An independent-samples t-test revealed that females (M = 82.0, SD = 8.2) scored significantly higher than males (M = 78.5, SD = 9.1), t(28) = 2.45, p = .021.”*
Case 2: One-Way ANOVA (Comparing Three+ Groups)
Steps:
-
Analyze → Compare Means → One-Way ANOVA
-
Move Exam_Score to “Dependent List.”
-
Move Group (e.g., Class_Section) to “Factor.”
-
Click Post Hoc → Select Tukey → OK.
Interpreting Output:
-
ANOVA Table: If p < 0.05, groups differ significantly.
-
Post-Hoc Tests: Identify which groups differ (e.g., Section A > Section B).
Reporting:
*”A one-way ANOVA showed significant differences in exam scores by class section, F(2, 27) = 4.67, p = .018. Tukey post-hoc tests indicated Section A (M = 85.2) scored higher than Section B (M = 77.4), p = .012.”*
Case 3: Pearson Correlation (Relationship Between Variables)
Steps:
-
Analyze → Correlate → Bivariate
-
Select variables (e.g., Study_Hours, Exam_Score).
-
Check Pearson → OK.
Interpreting Output:
-
Correlation Coefficient (r):
-
0 to 0.3 = Weak
-
0.3 to 0.7 = Moderate
-
0.7+ = Strong
-
-
Sig. (p-value): If p < 0.05, the correlation is significant.
Reporting:
*”A Pearson correlation revealed a moderate positive relationship between study hours and exam scores, r(28) = .52, p = .003.”*
Case 4: Chi-Square Test (Categorical Associations)
Steps:
-
Analyze → Descriptive Statistics → Crosstabs
-
Move one variable to Rows (e.g., Gender), another to Columns (e.g., Pass/Fail).
-
Click Statistics → Check Chi-Square → OK.
Interpreting Output:
-
Pearson Chi-Square: If p < 0.05, the association is significant.
Reporting:
*”A chi-square test indicated a significant association between gender and pass/fail rates, χ²(1) = 5.67, p = .017.”*

Creating Tables and Graphs
Generating Tables:
-
Right-click output tables → Copy → Paste into Word.
-
Use APA formatting (e.g., italicize headers, align decimals).
Creating Graphs:
-
Graphs → Chart Builder
-
Select type (Bar, Scatter, Histogram).
-
Drag variables to axes → Click OK.
Example:
-
Bar Chart: Compare group means.
-
Scatterplot: Visualize correlations.
Writing the Interpretation
Structure your interpretation with:
-
Objective: Restate the research question.
-
Method: Test used (e.g., “An independent t-test was conducted…”).
-
Results: Key statistics (means, p-values, effect sizes).
-
Conclusion: Answer the research question.
Example:
*”The analysis compared exam scores between male and female students using an independent t-test. Results showed females scored significantly higher (M = 82.0) than males (M = 78.5), t(28) = 2.45, p = .021. This suggests gender may influence academic performance.”*
Proofreading and Submission
✔ Check:
-
All tests align with the assignment requirements.
-
No missing values/errors in output.
-
Interpretation is clear and concise.
✔ Save: -
SPSS Data File (.sav)
-
Output File (.spv)
-
Export tables/graphs to Word/PDF.

Conclusion
Completing an SPSS assignment involves:
-
Understanding requirements (hypothesis, variables, tests).
-
Preparing data (entry, cleaning, screening).
-
Running analyses (descriptives, t-tests, ANOVA, etc.).
-
Interpreting and reporting results (tables, graphs, written summary).
By following this structured approach, you can efficiently tackle SPSS assignments with confidence.
Needs help with similar assignment?
We are available 24x7 to deliver the best services and assignment ready within 3-4 hours? Order a custom-written, plagiarism-free paper