Tips for Interpreting SPSS Regression Results Like a Pro|2025
Discover essential tips for interpreting SPSS regression results. Learn how to understand coefficients, p-values, and R-squared values to draw accurate conclusions from your data analysis! Regression analysis is a cornerstone of statistical research, helping analysts understand relationships between variables and make predictions. SPSS (Statistical Package for the Social Sciences) is a popular software for running regression analyses due to its user-friendly interface and robust features. However, interpreting SPSS regression results effectively requires a clear understanding of statistical concepts and best practices. This guide offers expert tips for interpreting SPSS regression results like a pro, ensuring you extract meaningful insights from your data.
Understanding Regression Analysis in SPSS
Regression analysis examines the relationship between dependent and independent variables. SPSS supports various types of regression, including:
- Linear Regression: Models the relationship between a continuous dependent variable and one or more independent variables.
- Logistic Regression: Used for binary or categorical dependent variables.
- Multiple Regression: Explores the impact of multiple independent variables on a dependent variable.
Key Components of SPSS Regression Output
When you run a regression analysis in SPSS, the output includes several critical sections:
- Model Summary: Provides R-squared and adjusted R-squared values, indicating the model’s explanatory power.
- ANOVA Table: Tests the overall significance of the regression model.
- Coefficients Table: Displays the regression coefficients, standard errors, and significance values for each predictor.
- Residuals Statistics: Offers insights into the accuracy of the predictions and identifies potential outliers.
Step-by-Step Guide to Interpreting SPSS Regression Results
1. Check the Model Fit
The first step in interpreting regression results is to evaluate how well the model fits the data:
- R-Squared Value:
- Found in the Model Summary table.
- Indicates the proportion of variance in the dependent variable explained by the independent variables.
- Values range from 0 to 1; higher values indicate better fit.
- Adjusted R-Squared:
- Adjusts for the number of predictors in the model.
- Useful for comparing models with different numbers of predictors.
- Standard Error of the Estimate:
- Measures the average distance between observed and predicted values.
- Smaller values indicate better fit.
2. Assess the Overall Model Significance
The ANOVA table provides a test of the overall significance of the regression model:
- F-Test:
- Evaluates whether the model explains a significant portion of variance in the dependent variable.
- A significant p-value (< 0.05) indicates the model is statistically significant.
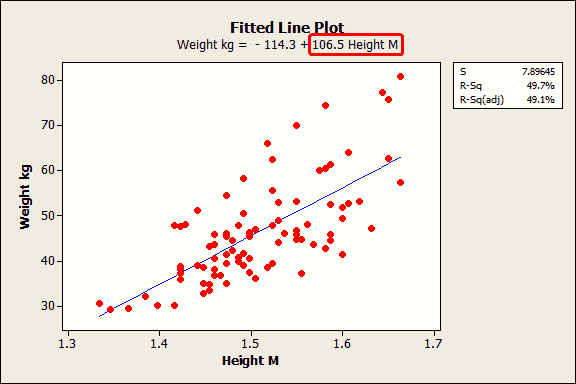
3. Examine Regression Coefficients
The Coefficients table is the heart of regression analysis. Key components include:
- Unstandardized Coefficients (B):
- Represent the change in the dependent variable for a one-unit change in the predictor, holding other variables constant.
- Example: If B = 2.5 for a price variable, a $1 increase in price leads to a 2.5-unit change in sales.
- Standardized Coefficients (Beta):
- Express the impact of predictors in standardized units, allowing for comparison across variables.
- Useful for identifying the strongest predictors.
- Significance (p-value):
- Tests whether the coefficient differs significantly from zero.
- Predictors with p < 0.05 are considered significant.
- Confidence Intervals:
- Provide a range within which the true coefficient value lies, with a specified level of confidence (usually 95%).
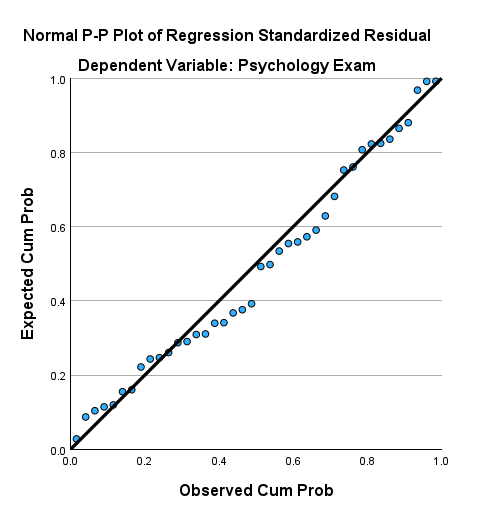
4. Evaluate Residuals
Residuals represent the differences between observed and predicted values. Analyzing residuals helps identify:
- Outliers: Cases with large residuals that may distort the model.
- Heteroscedasticity: Unequal variance in residuals across levels of the predictor variable.
Use residual plots (Graphs > Legacy Dialogs > Scatter/Dot) to visualize patterns and check assumptions.
5. Test for Multicollinearity
Multicollinearity occurs when independent variables are highly correlated, potentially biasing coefficient estimates. Check:
- Variance Inflation Factor (VIF):
- Found in the Coefficients table if requested (Statistics > Collinearity Diagnostics).
- VIF > 10 indicates problematic multicollinearity.
- Tolerance:
- Inverse of VIF; values < 0.1 suggest multicollinearity.
6. Interpret Logistic Regression Results
For logistic regression, SPSS provides additional outputs:
- Odds Ratios (Exp(B)):
- Represent the change in odds of the dependent event occurring for a one-unit change in the predictor.
- Example: Exp(B) = 1.5 indicates a 50% increase in odds per unit increase in the predictor.
- Classification Table:
- Displays the accuracy of the model’s predictions.
- Pseudo R-Squared Values:
- Includes Cox & Snell and Nagelkerke values, which approximate model fit.

Common Challenges and Solutions
1. Non-Significant Predictors
- Challenge: Some predictors may not significantly impact the dependent variable.
- Solution: Consider removing non-significant variables or exploring interactions.
2. Overfitting
- Challenge: Including too many predictors can lead to overfitting.
- Solution: Use stepwise regression or cross-validation to simplify the model.
3. Violated Assumptions
- Challenge: Regression assumes linearity, normality, and homoscedasticity.
- Solution: Transform variables or use non-parametric methods if assumptions are violated.
Tips for Professional-Level Interpretation
- Contextualize Results:
- Relate findings to the research question and domain knowledge.
- Example: Highlight practical implications for business or policy.
- Use Visuals:
- Enhance interpretation with scatterplots, histograms, and line graphs.
- SPSS’s Chart Builder makes it easy to create professional visuals.
- Report Effect Sizes:
- Include effect sizes (e.g., R-squared, standardized coefficients) to convey the magnitude of relationships.
- Validate the Model:
- Split the dataset into training and testing sets (Data > Select Cases) to test model generalizability.
Applications of SPSS Regression Analysis
SPSS regression is widely used in various fields:
- Business: Forecasting sales, analyzing customer satisfaction.
- Healthcare: Predicting patient outcomes, evaluating treatment efficacy.
- Education: Examining factors influencing academic performance.
- Social Sciences: Investigating relationships between demographic and behavioral variables.
Learning Resources for SPSS Regression
- IBM SPSS Tutorials: Access official guides and examples.
- Books: Reference texts like Discovering Statistics Using SPSS by Andy Field.
- Online Courses: Platforms like Coursera and LinkedIn Learning offer SPSS training.
- Community Forums: Engage with users on ResearchGate, Stack Overflow, and SPSS user groups.
Conclusion
Interpreting SPSS regression results like a pro requires attention to detail, a solid understanding of statistical principles, and a clear focus on research objectives. By following this guide, you can effectively evaluate model fit, analyze coefficients, and draw meaningful conclusions from your regression analysis. Practice these tips, leverage available resources, and continue honing your skills to excel in your data analysis endeavors.
Needs help with similar assignment?
We are available 24x7 to deliver the best services and assignment ready within 3-4 hours? Order a custom-written, plagiarism-free paper
