Proven Strategies to Boost GPA|2025
Explore proven strategies to boost GPA with expert tips on time management, study techniques, and effective learning methods. Start improving your academic performance today!
Achieving a high Grade Point Average (GPA) is a common goal for students at every academic level. Whether you’re in high school or college, adopting proven strategies can significantly improve your GPA and set you up for future success. This guide explores actionable steps tailored for high school and college students, with additional insights into overcoming challenging GPA scenarios and leveraging tools like GPA calculators.
.jpg)
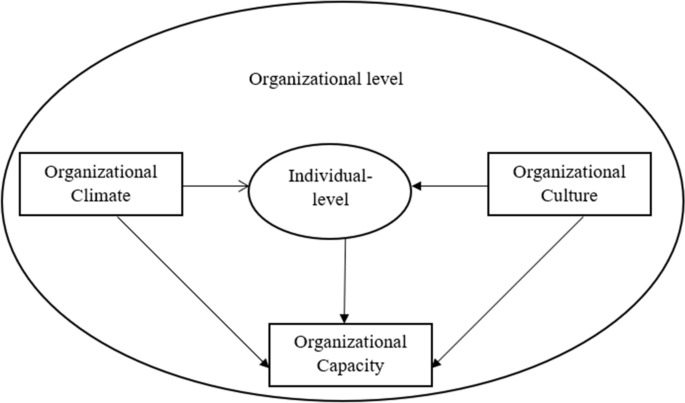
Understanding GPA
Before diving into strategies, it’s essential to understand what a GPA is and how it’s calculated. A GPA reflects your overall academic performance and is often calculated on a 4.0 scale. Grades from individual courses are weighted based on their credit hours, and the cumulative GPA is the average of these scores.
Proven Strategies to Boost GPA in High School
High school students aiming to improve their GPA can follow these steps:
Stay Organized
Use planners or digital apps to track assignments, tests, and project deadlines. Staying organized prevents last-minute cramming and ensures consistent performance.
Prioritize Core Subjects
Focus on subjects that carry more weight in GPA calculations, such as math, science, and English.
Develop Strong Study Habits
- Create a study schedule and stick to it.
- Use active recall and spaced repetition for better retention.
- Form study groups for collaborative learning.
Seek Help When Needed
- Don’t hesitate to ask teachers for clarification.
- Use tutoring services or online resources for challenging subjects.
Take Honors or AP Classes
Advanced Placement (AP) and honors courses often have weighted grades, which can boost your GPA if you perform well.
Participate in Extracurricular Activities
While not directly impacting your GPA, activities like debate or science clubs can improve skills that translate to academic success.
Proven Strategies to Boost GPA in College
College students face unique challenges but can also take advantage of specific strategies:
Choose Courses Strategically
- Balance challenging courses with ones you are confident in.
- Avoid overloading your schedule.
Attend Every Class
Attendance often correlates with better grades. Take notes and actively participate to reinforce learning.
Master Time Management
- Use time-blocking techniques to allocate specific times for studying, attending classes, and relaxing.
- Limit distractions like social media during study sessions.
Use Campus Resources
- Take advantage of academic advising, writing centers, and peer tutoring.
- Participate in workshops or seminars related to academic skills.
Build Relationships with Professors
- Attend office hours to seek guidance.
- Building rapport with professors can lead to mentorship opportunities and academic support.
Improve Exam Techniques
- Practice past papers to familiarize yourself with exam formats.
- Manage your time effectively during exams to complete all sections.
Can I Raise My GPA from 2.5 to 3.0 in One Semester?
Yes, it is possible to raise your GPA significantly in one semester with focused effort. Strategies include:
- Retake Courses: Retaking courses where you scored low can replace poor grades in your GPA calculation.
- Excel in Current Courses: Aim for A’s in all current courses to maximize your semester GPA.
- Leverage Extra Credit Opportunities: Participate in projects or assignments that offer additional grade points.
- Seek Academic Support: Work with tutors or study groups to excel in difficult subjects.
Using a GPA Calculator
GPA calculators are valuable tools for setting realistic academic goals. You can:
- Input your current grades and credit hours to determine your current GPA.
- Experiment with potential grades to see how they will impact your cumulative GPA.
- Plan your course load based on desired GPA outcomes.
How to Get a Higher GPA in High School
To achieve a higher GPA in high school, consider:
- Improving Test Scores: Focus on acing tests and quizzes as they often contribute significantly to grades.
- Participating Actively: Class participation can sometimes improve borderline grades.
- Leveraging Online Resources: Use platforms like Khan Academy for additional learning support.
- Communicating with Teachers: Request feedback on assignments and areas for improvement.
How to Get a High GPA in University
University students aiming for a high GPA should:
- Stay Consistent: Prioritize consistency in performance across all semesters.
- Engage in Peer Learning: Study with classmates to gain diverse perspectives.
- Focus on Major Courses: Excelling in major-specific courses can significantly boost your GPA.
- Utilize Technology: Use apps like Evernote or Notion to organize your academic life.

Can I Raise My GPA from 1.6 to 2.0 in One Semester?
Raising your GPA from 1.6 to 2.0 in one semester is challenging but achievable. Focus on:
- Maximizing Grades in All Courses: Aim for A’s and B’s to improve your GPA quickly.
- Using Academic Support: Seek help from advisors or tutors to address weak areas.
- Dropping Low-Performing Courses: If allowed, drop courses where you’re likely to score poorly and replace them with manageable ones.
How to Get a 3.0 GPA in College
Achieving a 3.0 GPA requires sustained effort:
- Set Clear Goals: Understand the grades needed in each course to reach your target GPA.
- Optimize Study Techniques: Use active learning methods, such as summarizing and self-quizzing.
- Stay Motivated: Celebrate small achievements to maintain momentum.
- Monitor Progress: Regularly calculate your GPA to stay on track.
Conclusion
Improving your GPA requires a combination of strategic planning, consistent effort, and effective use of resources. Whether you’re in high school or college, adopting these proven strategies can help you achieve your academic goals. Tools like GPA calculators, coupled with personalized study plans, ensure that your hard work translates into measurable success.
Needs help with similar assignment?
We are available 24x7 to deliver the best services and assignment ready within 3-4 hours? Order a custom-written, plagiarism-free paper