STATA Homework Help: A Comprehensive Guide to Using STATA for Research and Homework Assignments|2025
Get professional STATA Homework Help for data analysis, statistical techniques, and coding solutions. Ensure accuracy and improve your grades with expert guidance.
In the modern era, the use of statistical software is essential for conducting data analysis in fields such as economics, sociology, public health, and political science. Among the most widely used statistical tools is STATA, a powerful software program for data management, statistical analysis, and graphics. STATA is often employed by researchers, students, and professionals for its versatility in handling complex data sets and performing advanced statistical techniques. However, many students struggle with using STATA effectively, especially when completing homework assignments or research projects that require data analysis.
This paper aims to provide an in-depth guide to help students understand and navigate the world of STATA. We will cover its primary functions, common homework tasks in STATA, tips for overcoming common challenges, and resources available for mastering the software. By the end of this paper, readers will have a clearer understanding of how to approach their STATA homework with confidence and improve their proficiency in using the software for various research tasks.

Overview of STATA Software
STATA is a statistical software package that allows users to manage, analyze, and visualize data. It is particularly popular among researchers in economics, sociology, political science, public health, and epidemiology. STATA is known for its user-friendly interface, extensive documentation, and ability to perform a wide range of statistical procedures, from basic descriptive statistics to complex econometric models.
STATA’s features include:
- Data management tools: It provides functionalities for cleaning, transforming, and structuring data.
- Statistical analysis: It supports a broad array of statistical methods such as regression analysis, hypothesis testing, survival analysis, and time-series analysis.
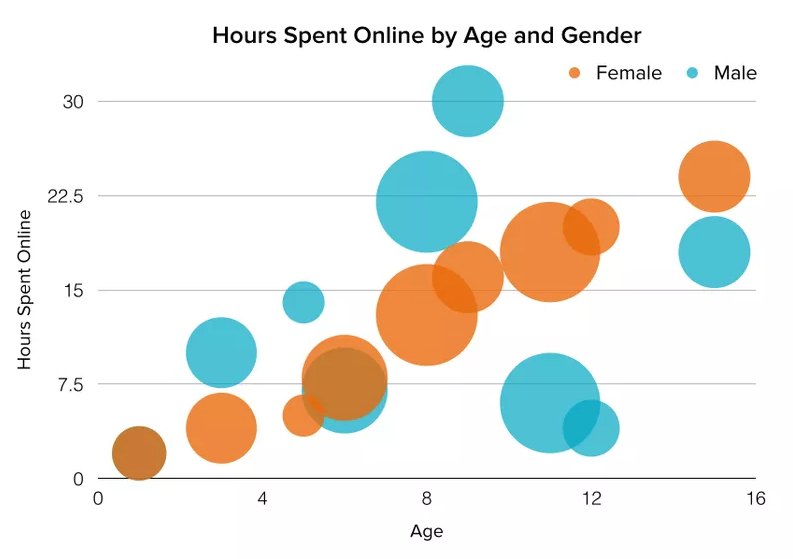
- Graphics and visualization: STATA enables users to create informative and customizable charts and graphs.
- Programming capabilities: For advanced users, STATA allows for automation and scripting of repetitive tasks.
STATA is widely used for both academic purposes (e.g., homework, dissertations) and professional tasks (e.g., policy analysis, market research).
Common Homework Tasks in STATA
STATA is commonly used in academic settings to complete assignments that require data analysis. Below are some common tasks that students might encounter in their STATA homework:
a. Data Cleaning and Transformation
Before conducting statistical analysis, it is essential to prepare the data. In STATA, data cleaning includes handling missing values, creating new variables, merging datasets, and reformatting variables. Common STATA commands used for data cleaning include:
- Descriptive Statistics:
summarize,tabulate, anddescribe - Missing Values:
replace,if, andmvdecode - Variable Creation:
generateandegen - Data Merging:
merge,append
b. Descriptive Statistics
Descriptive statistics provide an overview of the main characteristics of a dataset. In STATA, students can generate summary statistics such as the mean, standard deviation, minimum, and maximum using commands like:
summarizefor continuous variablestabulatefor categorical variableshistogramto visualize distributions
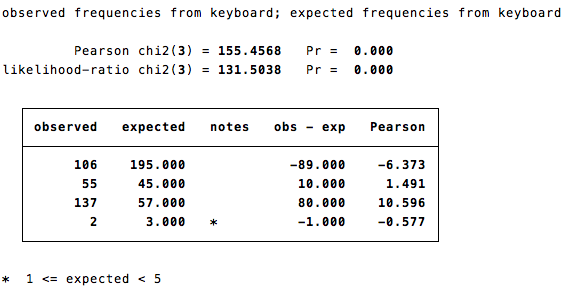
c. Inferential Statistics and Hypothesis Testing
Students frequently use STATA to perform hypothesis tests, including t-tests, chi-square tests, and ANOVA. For example, a two-sample t-test can be conducted using:
ttest variable, by(group)for comparing the means of two groups.
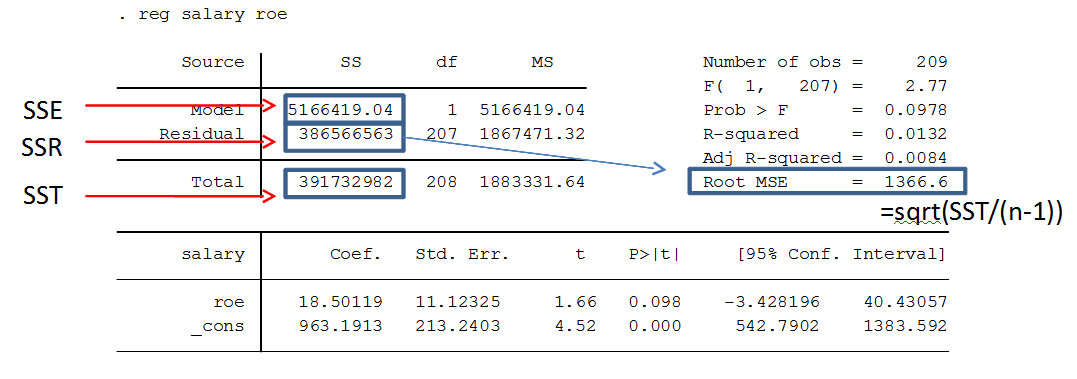
d. Regression Analysis
Regression analysis is a staple of statistical homework. Students may be asked to perform linear regression, logistic regression, or multiple regression analyses. STATA provides easy-to-use commands for regression:
- Linear Regression:
regress dependent_var independent_var - Logistic Regression:
logit dependent_var independent_vars
e. Time-Series and Panel Data Analysis
STATA’s capabilities extend to time-series and panel data analysis, often required in economics or political science assignments. Students might be tasked with running models like autoregressive models or fixed/random effects regression.

Tips for Completing STATA Homework
Here are some tips to help students work through their STATA homework effectively:
a. Understand the Problem Before Using STATA
It is essential to read the assignment carefully and understand the problem before jumping into STATA. Make sure to define the research question, identify the variables needed, and determine the statistical techniques required.
b. Organize the Data
When working with datasets in STATA, it is important to structure and clean the data properly. Organizing the data will help avoid errors during analysis. This involves checking for missing values, creating necessary variables, and ensuring the dataset is in the appropriate format.
c. Break the Homework Into Smaller Tasks
STATA commands can be overwhelming if you try to complete everything at once. Break the assignment into smaller parts, such as cleaning the data first, then running descriptive statistics, followed by hypothesis testing, and finally running regression models.
d. Use STATA Help Resources
STATA provides robust documentation and in-built help tools. The help command in STATA is an invaluable resource for understanding commands and functions. Students should make use of these resources when encountering issues or confusion. Additionally, online tutorials, forums, and study guides can provide step-by-step instructions.
e. Practice Regularly
Like any statistical software, STATA requires practice to master. Students should practice using the software regularly, not just when completing homework, to become comfortable with the commands and functions.
Overcoming Common Challenges in STATA
While STATA is user-friendly, students may still face challenges, especially when they encounter more complex analyses. Here are some common challenges and solutions:
a. Syntax Errors
STATA commands require precise syntax. A small error, such as a missing comma or incorrect variable name, can lead to errors. To resolve this, students should carefully check their commands and use the log feature to track the results of each command.
b. Data Issues
Dealing with large datasets or improperly formatted data can create problems. To handle this, students should ensure that the data is clean and organized, and that variables are correctly labeled and formatted.
c. Statistical Interpretation
Interpreting statistical outputs in STATA can be challenging, especially for beginners. Students should familiarize themselves with common statistical terms and output interpretations, such as p-values, confidence intervals, and regression coefficients.

Resources for Learning STATA
To master STATA and overcome homework challenges, students can make use of several resources:
a. STATA Documentation
The STATA manuals and online help guides are comprehensive resources for learning the software. They cover both basic and advanced topics and provide syntax examples.
b. Online Forums and Communities
There are many online communities, such as Stack Overflow and STATA’s own forums, where students can ask questions and learn from others’ experiences. Engaging with these communities can provide valuable insights into problem-solving.
c. Tutorials and Courses
Many universities and online platforms offer STATA tutorials and courses. Websites like Coursera, Udemy, and YouTube have beginner and advanced-level tutorials that walk students through STATA’s features and functionalities.
Conclusion
STATA is an indispensable tool for data analysis in academic and professional research. By understanding its capabilities, mastering the commands, and practicing regularly, students can complete their STATA homework with confidence and efficiency. Whether performing basic descriptive statistics or complex regression analyses, STATA offers a wide range of tools for data analysis. Utilizing the resources available, including online help and communities, can greatly enhance a student’s ability to use STATA effectively. As students continue to work with STATA, they will not only improve their technical skills but also gain a deeper understanding of statistical concepts and their application in real-world research.
Needs help with similar assignment?
We are available 24x7 to deliver the best services and assignment ready within 3-4 hours? Order a custom-written, plagiarism-free paper